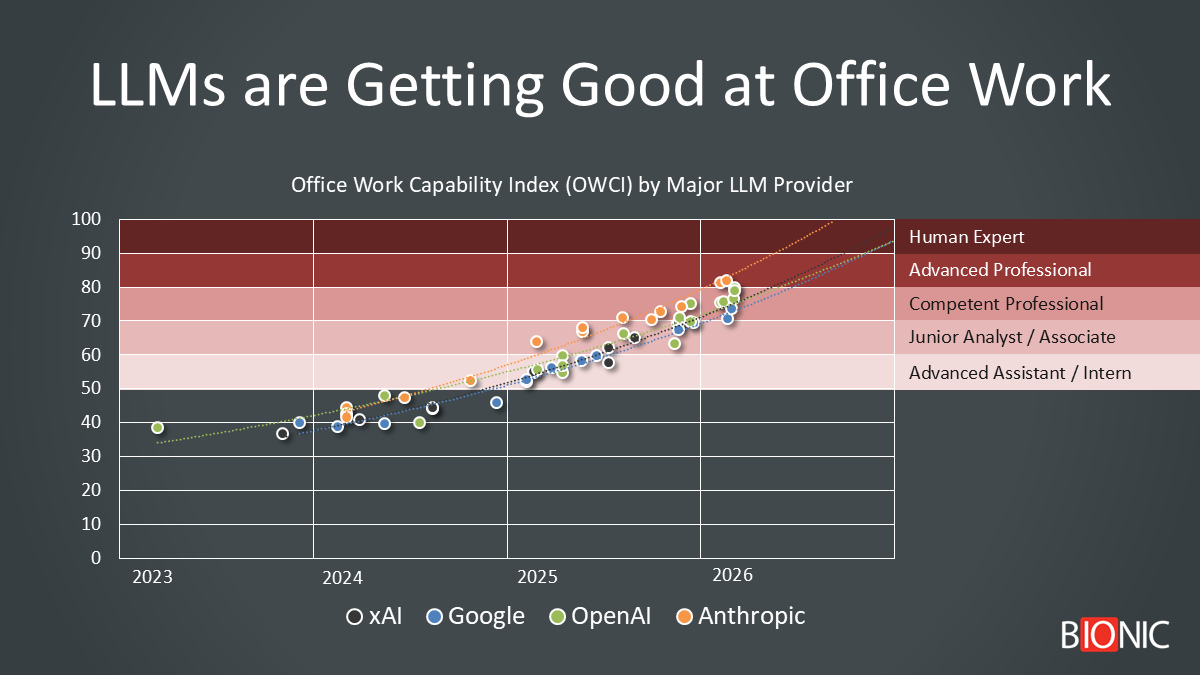
Office Work Capability Index (OWCI) by major LLM provider. Source: Bionic analysis of public benchmark results and model-release data.
What the chart suggests
If the extrapolated trend lines in the chart continue to hold, the first frontier models appear likely to reach human-expert parity (OWCI 100) in late 2026, with the broader frontier pack converging around 2027. That is a directional extrapolation from the chart, not a certainty: progress is uneven, benchmark coverage is sparse, and real-world deployment usually lags model capability.
For the last few years, the two most important questions in our industry have also been the hardest to answer:
- How does AI compare to humans for office work?
- When will AI match and surpass humans?
The problem is not a lack of benchmarks. It is the opposite.
The market is flooded with numbers – MMLU, MMLU-Pro, SWE-Bench, GAIA, GDPval – but the coverage is sparse, the definitions are different, and vendors rarely report the exact same set of scores. One benchmark measures exam-style reasoning. Another measures software bug fixing. Another measures tool use in realistic workflows. Even when the numbers are strong, it’s often unclear what they mean for the actual work done by media planners, media buyers, analysts, media coordinators, and ad operations teams.
That frustration led us to create the Office Work Capability Index (OWCI): a simple 0–100 framework that translates fragmented benchmark data into one practical question: how capable is this model, relative to a human professional, at performing real office work?
This is not a new benchmark. It is a translation of existing benchmarks, with the goal to make the benchmark landscape useful for creating a practical AI strategy and action plan.
Why we built the OWCI
Most benchmark conversations miss the thing executives actually care about. They answer, “How good is the model on this test?” not, “What level of human work can this system credibly perform?”
GDPval is a major step forward because it evaluates real-world, economically valuable tasks across 44 occupations, using work products like legal briefs, engineering blueprints, customer support conversations, and spreadsheets. But it is still early, still one-shot in many cases, and still unevenly reported across providers.
GAIA is closer to office work than classic academic benchmarks because it tests multi-step questions that require reasoning, tool use, and browsing. Its original paper reported a roughly 92% human baseline, which is one reason it is so useful: it highlights the gap between impressive model outputs and robust human task completion.
MMLU remains a useful proxy for broad knowledge and reasoning, but the newer MMLU-Pro is harder and more stable. Its creators expanded the answer set from four to ten options and designed it to be more reasoning-heavy, precisely because classic MMLU had become too easy for frontier systems.
How the OWCI works
OWCI is a weighted composite on a 0–100 scale where 100 represents human expert-level office work capability.
The components of the OWCI are sources from existing benchmarks:
- GDPval-style knowledge work (35%) – Closest proxy for economically valuable office work
- GAIA workflow completion (25%) – Multi-step execution, tool use, and realistic assistant behavior
- MMLU / MMLU-Pro reasoning (25%) – General knowledge and analytical reasoning
- SWE-Bench implementation (15%) – Structured problem solving and execution discipline
A crucial methodological choice is that missing data is not treated as zero.
Public benchmark coverage is inconsistent. If a provider never published a GAIA score for a given release, that should not automatically crater its ranking.
Instead, OWCI uses the benchmark evidence available for that model, then estimates the missing pieces conservatively using adjacent benchmark performance and provider trendlines. That produces a cleaner apples-to-apples comparison over time.
To see the research and data behind the OWCI: Download the Raw Data
The OWCI Capabilities Ladder
The OWCI capabilities ladder maps reasonably well to workplace intuition:
- Scores in the 50s look like structured administrative support
- Scores in the 60s look like advanced assistant or intern-level work
- Scores in the 70s look like junior analyst capability
- Scores in the 80s look like competent professional performance
- Scores in the 90s signal expert-level human performance
- Scores >100 indicate super-human performance
What we found
In 2024, AI became a helpful assistant
The first clear finding is that something important changed in 2024.
That is the year frontier models moved from “interesting productivity tool” to “credible junior knowledge worker” on a meaningful share of office tasks.
That conclusion is consistent with field evidence. In the NBER field study on customer support work, generative AI increased productivity by about 14% on average and by roughly 35% for less experienced workers. Those are not lab numbers. They are real workflow numbers.
In 2026, AI became a competent collaborator
The second finding is that frontier models in 2026 appear to be clustering around the boundary between junior analyst and competent professional for structured office work.
LLMs are increasingly strong at summarizing documents, drafting memos, extracting data, generating spreadsheets, synthesizing research, and producing first-pass analytical outputs.
AI is now becoming an expert co-worker
The third finding is that the bottleneck has shifted.
The old question was whether models could answer hard questions. The new question is whether they can complete workflows reliably. That is why benchmarks such as GDPval and GAIA matter more than benchmark trivia. They measure work products, tool use, and longer-horizon tasks that are much closer to the shape of actual office work.
So, when will AI surpass humans?
If you take the attached chart at face value and extend the trend lines, the first frontier systems appear likely to reach OWCI 100 in late 2026, with the broader frontier cluster reaching that level around 2027. Put differently: the image suggests that human-expert parity is not decades away; it is plausibly within the next one to two product cycles.
But that needs a major caveat. A benchmark crossing is not the same thing as broad economic replacement. Anthropic’s March 2026 labor-market analysis explicitly says actual coverage remains only a fraction of theoretical capability, and it finds no systematic increase in unemployment for the most exposed workers so far, though it does see suggestive evidence that younger-worker hiring has softened in more exposed occupations.
That caution is echoed by the ECB’s March 2026 analysis, which found that firms making significant use of AI were about 4% more likely to hire additional staff. In other words, adoption today still looks at least partly like augmentation and growth, not just substitution.
The case for acceleration – and the case for caution
The bullish case is easy to see.
Frontier model releases keep improving on reasoning, coding, context length, and tool use. OpenAI’s GDPval write-up argues that economically valuable task benchmarks are the right way to ground conversations about progress. Anthropic’s Economic Index shows increasing automation of office and administrative support tasks in API usage, including email management, document processing, scheduling, and customer-relationship work.
The skeptical case is just as important.
Benchmark reporting is selective. Real office work includes ambiguity, politics, compliance, and accountability. Validation overhead matters. And even strong benchmark performance does not mean organizations will deploy AI fast enough, safely enough, or coherently enough to eliminate jobs at the same pace that model capability improves.
The World Economic Forum continues to emphasize analytical thinking, resilience, AI literacy, and continuous learning as rising priorities. That is a helpful reminder: the future of office work is unlikely to be “humans out, machines in.”
It is more likely to be a rapid redesign of which parts of the job belong to software, which belong to humans, and which belong to the combination.
What does this mean for media planning and media buying?
This is where the discussion becomes very practical for agencies.
In our recent post, How AI Will Reshape Media Planning and Media Buying, we argued that the most exposed part of the function is the operational layer: data gathering, taxonomy mapping, first-pass scenarios, spreadsheet assembly, pacing checks, dashboard commentary, QA, workflow administration, and repetitive reporting.
OWCI reinforces that conclusion.
If frontier models are already operating in the 70s and 80s on a human-comparative office-work scale, then a large share of agency operations is already in the zone of heavy augmentation – and some of it is entering the zone of outright automation.
The work most exposed over the next 12 to 24 months includes first-pass media allocations, audience segmentation, budget pacing analysis, reporting narratives, proposal support, reconciliation support, naming-convention QA, and meeting-note extraction. The work that remains human for longer is the work agencies should want to own anyway: business framing, tradeoff decisions, client communication, seller negotiation, measurement design, governance, and accountability.
What agency leaders should do now
- Redesign planner and buyer roles around diagnosis, orchestration, judgment, and client counsel rather than manual execution.
- Audit your top workflows by hours consumed and classify them as automate, augment, supervise, or retain.
- Build a system-of-record layer that grounds AI in real campaign, pricing, workflow, and financial data.
- Rebuild the apprenticeship model so junior staff learn judgment even if AI absorbs the old manual tasks.
- Move the client conversation away from labor-hours and toward outcomes, governance, and control.
Bottom line
The benchmark story around office work is messy. That is exactly why OWCI matters. It gives you a way to interpret fragmented benchmark data in terms that are operationally useful.
The conclusion is simple: AI is no longer merely an assistant for office work. It is becoming a capable junior knowledge worker, and in structured domains it is already approaching competent professional performance. If the current trend lines hold, the first frontier systems may touch human-expert parity in late 2026, with the broader market approaching that level in 2027.
For advertising agencies, the implication is not that media planning and buying disappear. It is that the operating mechanics of the function compress, while the strategic layer becomes more valuable.
The winners will not be the firms that defend manual workflow. They will be the firms that turn AI into a better control layer, a better advisory model, and a better client experience.
Continue the conversation
If you lead media planning, media buying, agency operations, or revenue operations, now is the time to map which workflows will be automated, which will be augmented, and which must remain human-led. Read the companion article and use it to pressure-test your operating model before the market does it for you.